Postgres Lock Queues, Migrations, and Timeouts
April 19, 2024 ( last updated : April 19, 2024 )
postgres
Postgres Lock Queues, Migrations, and Timeouts
Imagine you are adding a new column to a table that sees a decent amount of traffic. For this example, let’s say we’re adding an age column to the users table:
ALTER TABLE users ADD COLUMN age integer;
We’re not setting a default value or adding a not null constraint so this should be a super fast migration, we check locally and…
> ALTER TABLE users ADD COLUMN age integer;
ALTER TABLE
Time: 9.956 ms
Lo-and-behold it finishes just as fast as we expected! We run the migration locally, in non-prod environments, everywhere — it’s blazing fast and we’ve done our due diligence. We ship the migration to production, run it, and… the app explodes as the users table grinds to a halt and stops responding to query requests entirely. What just happened?!
NOTE: this scenario is something I encountered in real-life, not just an example to talk about lock queues 😄
Postgres Lock Modes
All queries in postgres acquire some kind of lock and, to quote the docs:
…PostgreSQL commands automatically acquire locks of appropriate modes to ensure that referenced tables are not dropped or modified in incompatible ways while the command executes
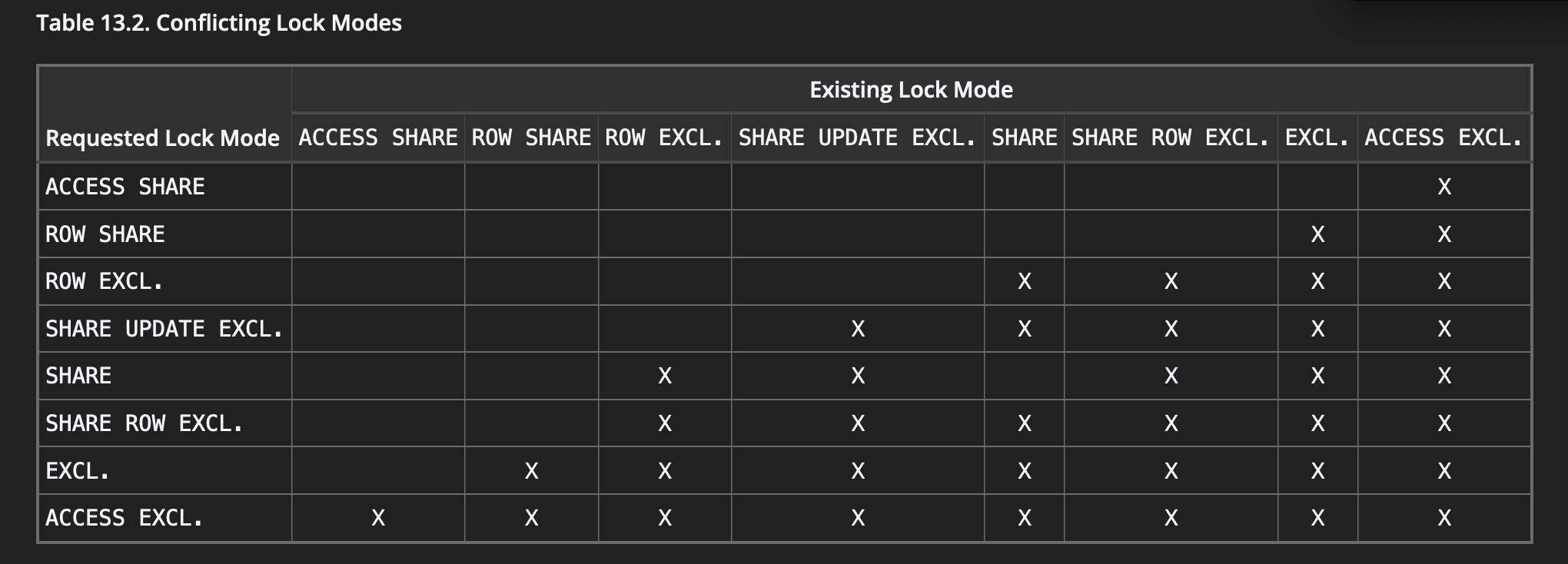
But not all locks in postgres are created equal, some lock rows, others tables and many locks allow other commands to still access data while the operation holds the lock. The table below shows which locks modes conflict with each other (X’s mean the modes conflict)
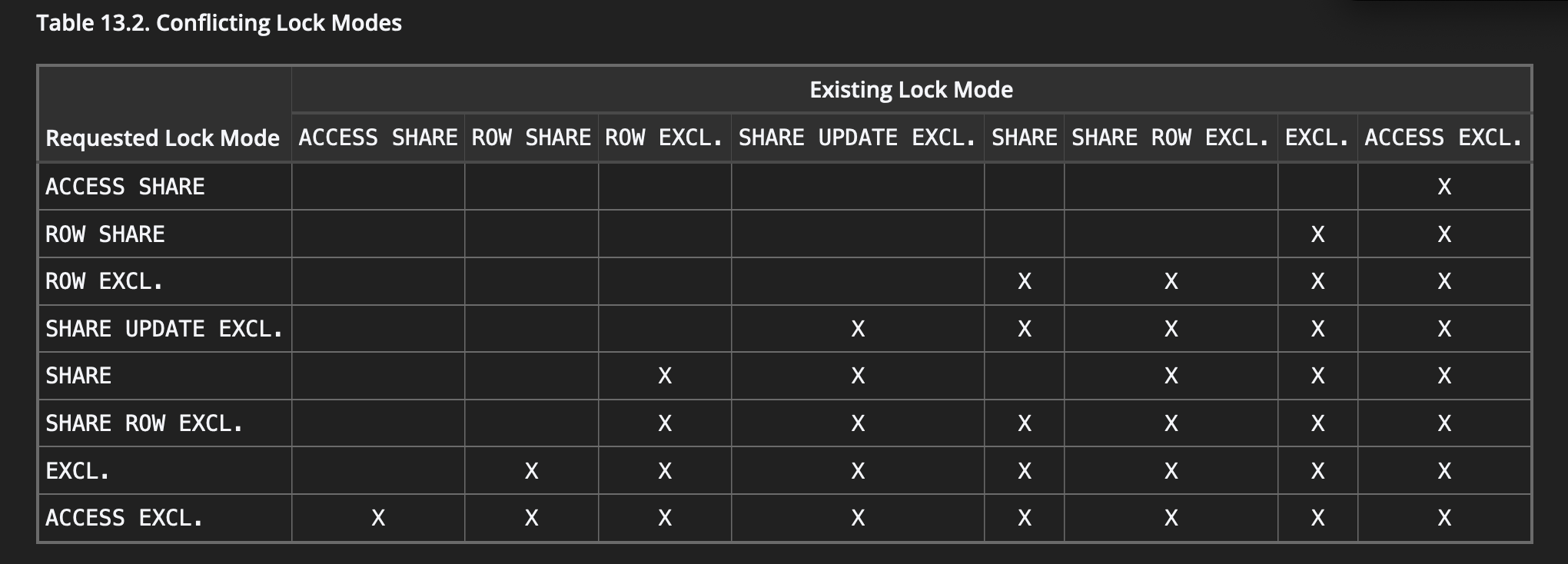
Table taken from the docs on table-level locks
This is why we can perform thousands of reads against a single row without a problem; reads require locks such as ROW EXCLUSIVE which do not conflict with each other.
The problem arises when we are executing statements that require stricter locks, such as most DDL statements which require ACCESS EXCLUSIVE locks. The ALTER TABLE from our example above requires such a lock; checking the table above, we see that ACCESS EXCLUSIVE is the strictest lock level, not permitting any other lock type concurrently.
Lock Queue
So what happens when two statements try to access the same table, but have conflicting locks?
Again quoting the PG docs
One server process blocks another if it either holds a lock that conflicts with the blocked process’s lock request (hard block), or is waiting for a lock that would conflict with the blocked process’s lock request and is ahead of it in the wait queue (soft block)
So when there are multiple queries with conflicting locks such as our example above, postgres puts these commands in a queue, waiting for the blocking queries to finish before allowing the next command to execute.
Example
Let’s simulate a long-running query that has an ACCESS EXCLUSIVE lock by opening a transaction, obtaining the lock and never closing it
> BEGIN;
BEGIN
> LOCK TABLE users IN ACCESS EXCLUSIVE MODE;
LOCK TABLE
-- don't commit this transaction
in another transaction we try doing a simple query
SELECT * FROM users LIMIT 1;
This query hangs since our first transaction still has the ACCESS EXCLUSIVE lock on the users table and this query is requesting a conflicting ACCESS EXCLUSIVE lock. This SELECT command sits in the lock queue until the original query finishes. Committing the original transaction will release the lock and allow the SELECT to return since there are no other commands in the queue.
Multiple Locks in The Queue (The Crux)
Going back to the original story, we run a query that requires a strict ACCESS EXCLUSIVE lock (which will prevent other queries from completing on that table), but we know this query should be fast, releasing the lock after 9ms… so why did it grind the table to a halt?
If there is a conflicting lock on a table or row, then commands get put into a queue. If there is another command that wants access to that table/row and there is an existing queue, then all subsequent commands get added to that queue, even if these commands do not conflict with the existing locks!.
This may be easiest to demonstrate via an example
Example
To simulate a long-running query, we open a transaction, locking the users table in share mode
> BEGIN;
BEGIN
> LOCK TABLE users IN ACCESS SHARE MODE;
LOCK TABLE
-- don't commit this transaction
Now our table is locked using ACCESS SHARE so commands that request a non-conflicting lock will execute without a problem
SELECT * FROM users LIMIT 1
-- a non-conflicting ACCESS SHARE lock, so it returns a user
but if we try to execute a command that requests a conflicting lock (such as ACCESS EXCLUSIVE), that command will hang, waiting in the queue until the conflicting lock is resolved.
ALTER TABLE users ADD COLUMN age integer;
-- hangs
Hanging, just like we expected!
Now what happens if we try to execute a command that does not conflict with the original lock, another ACCESS SHARE, let’s use the same SELECT we saw succeed earlier:
SELECT * FROM users LIMIT 1
-- hangs
This hangs, even though the ACCESS SHARE lock doesn’t conflict with the table lock. This is because there is already a lock queue so our command needs to wait for the operations ahead of it in the lock queue to finish before it’s allowed to access the data.
If we commit the original transaction, the lock releases, and the commands in the queue are able to process.
So, What Can You Do?
Handle Long-Running Queries
The obvious answer may be “don’t have long-running queries”, but we all know that isn’t always possible in real life. Another option is to move these long-running queries (and maybe any other reads) to a read-replica to prevent holding conflicting locks for a long period of time, but that can be expensive. While we did eventually do that at my work, there’s a quick-fix that we implemented first.
Timeouts
Postgres gives us the option to configure a couple timeouts, canceling any command that takes longer than the configured value. The first is statement_timeout and the second is lock_timeout.
Setting the statement_timeout can be handled at the application, load balancer or at the individual command level and will kill any queries that take longer than the timeout. statement_timeout starts the clock when the command reaches the database so it will take lock queue time into account and would have prevented the issue we saw above. In general a well-tuned statement_timeout can help prevent rogue queries from stalling your database.
If you want to allow long-running queries, but want prevent long waits for a lock, you can reach for lock_timeout, it works in a similar way to statement_timeout but only measures how long the command waits for lock acquisition.